| Porting my blog for the second time, render posts part 8 |
Aleksandra 1 November 2015 |
Porting my blog for the second time, render posts part 9
This is post #31 of my series about how I port this blog from Blogengine.NET 2.5 ASPX on a Windows Server 2003 to a Linux Ubuntu server, Apache2, MySQL and PHP. A so called LAMP. The introduction to this project can be found in this blog post /post/Porting-my-blog-for-the-second-time-Project-can-start.
I was just about to start working on resolving internal aspx links when I discovered a post without an image. It turned out to be the resolving routine failing. I fixed that first.
# http://www.jens.malmgren.nl/post/Porting-my-blog-for-the-second-time-render-posts-part-9.aspx
$tag =~ s/(.*?)(https?://|/image)(.+?)(["'])/$1{URL:$iDatabaseIDofThisURLentry}$4/i;
The replace routine was missing the case insensitive operator '/i' so that 'Image' would not match with 'image', and that was necessary.
Then I could start work on the aspx challenge. Lets recap the situation with the aspx links. In my old blog each page are stored in a page ending with aspx. In my new blog I will not have that. I will have an entirely different structure. One way of solving this could be to fix the links during import the way they will look like in the future but that will not be as elegant as the URL resolve routine for for the images. My current solution for images makes it possible for me to place the images anywhere and then I can replace the links to all images in one place. I would like to have a similar "freedom" with internal links. So that is the goal, how is this supposed to look like?
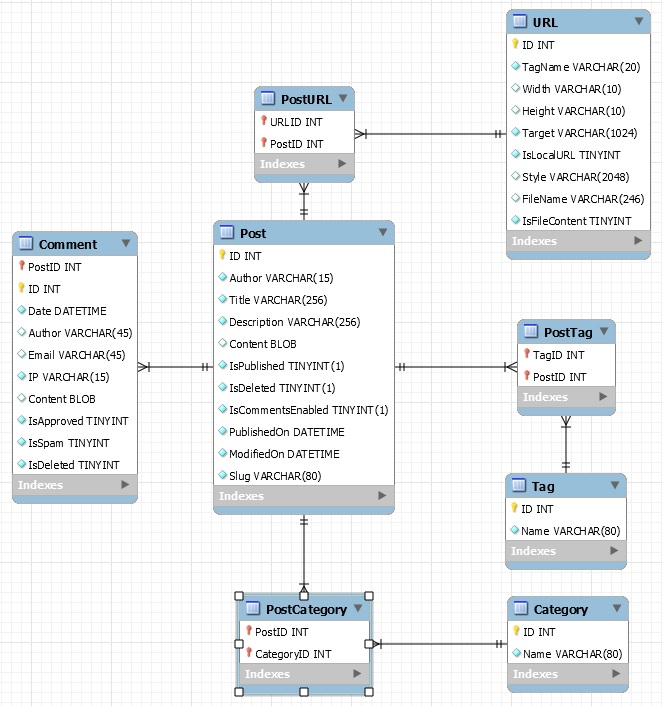
I talked about the design of the URL entity in this post /post/Porting-my-blog-for-the-second-time-images-part-2. When I designed this feature I had to have a place to store the URLs available in a blog post. So the Post entity is connected to URL entities via PostURL. All the time I have seen this as the storage of links available in a Post. Now I realize that the relation between a Post and an URL can be of two kinds. One kind of relation is that the URL is indeed available in a post. The other kind is that an URL points to a post.
To make this possible I would need to have an extra field in the PostURL entity. For example a TINYINT called IsLink. When it is 1 the URL is a link to the Post. When it is 0 it is an URL stored in a post.

There is more to this. It will get complex now. A Post can store a specific URL. So far it is easy. Suppose that if the content of the Post contains the URL place holder then the database also has the URL entity and it is connected to the Post via the PostURL entity and vice versa. It is only possible to have that same URL connected once to a Post in the database though because when we got a tuple describing the connection between a Post and an URL then we cannot have another identical tuple. It is of course possible to use the same URL place holder several times in the content so there is no limit there but in the database there is this limit due to the primary key tuple. But how about if you want to link from a Post to itself? In that case the URL has to be stored in the Post so there would be a PostURL record linking the Post and the URL where IsLink was 0 and then there has to be another PostURL record where IsLink is 1. But this is not possible because the combined primary key tuple so this is impossible unless also IsLink is part of the primary key. But, since I don't want to make it possible to link a Post to itself I am fine with this.
The current handling of URLs need to be changed so that the URL records are created as IsLink = 0. It is very easy to do this by setting the default value to 0 already in the Schema. So I did. While at it I decided that IsLink should not be allowed to be null and by doing so the rhomboid at IsLink in the ER turned light blue. Those little clues that makes life easier if you just pay attention!
ERROR: Error 1265: Data truncated for column 'IsLink' at row 1
This is so typical! Just doing something as simple as edit the schema and then it is not working anymore. There we have these emotions again "what is going on here?" yada yada. Well, I got it figured out! First I added a field called IsLink. So it got added to the database with all values set to null. Then I update the database to tell it that IsLink cannot be null. Well, cannot do that because it is already null everywhere. So what to do? I deleted the field IsLink. Synced with the database. Then I added the field IsLink again as a NotNull field with default value 0. Really easy! Grmbl...
So what to do next? I think that the easiest is to add a new procedure in the Perl program after all Post records are created in the database. In that procedure all URL records will be analyzed. If the URL is an internal URL ending with aspx then that URL will be converted to a Slug in the form as the new blog has the slugs. This means that the slug cleaning routine needs to be used. Then with help of the slug it is possible to do a lookup in the database to find out what Post the internal link is pointing to and then create a PostURL connection between the URL and the Post with IsLink = 1. Nice!
Not nice. More like a down into the rabbit hole experience. I found that I had three links from the time when the blog was hosted at Blogger and these links was also broken. I solved these by simply doing a search and replace into the BlogEngine.NET form of links and from there I had a way to resolve the links and match up with a proper slug.
Proper slug? Ha! I found I had an error in the slug cleaning. Watch this expression:
$dictStringFieldToValue{"slug"} =~ s/^-?(.*)-?$/$1/;
The goal with this expression was that it would remove any preceding and trailing dash signs from the slug. It only removed preceding dash signs but since they were few that was not such a great achievement. What about the trailing dash signs? Well is there was any trailing dash to be found by -* then they were competing with .* but since .* was much more eager than -* and . match anything including dash so there was no room to match any trailing dash signs. When .* is made lazy with .*? then the trailing dashes would be found. Pff... Like this:
$dictStringFieldToValue{"slug"} =~ s/^-*(.*?)-*$/$1/;
If you just know what you are doing and put one foot after another, at some point you will get there.
So I got all this fixed. Is it fine then? No. It turned out to be so that in the very very first blog post done on Blogger Google gave me a little present. It included a little tracker image one by one pixel in the text.
All these years I had that tracker pixel dangling in my first blog post. And now it caused my last slug failure. So I made a routine removing it.
$dictStringFieldToValue{"content"} =~ s/≺div class="blogger-post-footer"≻≺img src=".*?" alt="" width="1" height="1" /≻≺/div≻//;
Funny that I had this "payload" next to a sentence where I am thanking Google for providing such good and free tools. As they usually say "When the service is free YOU are the product". And others don't like this saying. Why? Is it too pithy and clever?
Whoahlaa!
Here is the final routine linking URLs to posts:
# http://www.jens.malmgren.nl/post/Porting-my-blog-for-the-second-time-render-posts-part-9.aspx
if ($setUpIsLinkPostURL)
{
my $sth = $dbh -≻ prepare('SELECT Target, ID FROM URL WHERE IsFileContent = 0 AND IsLocalURL = 1;');
$sth-≻execute( );
my %dictURLIDToPostID = ();
while (my @row = $sth-≻fetchrow_array)
{
my $strTargetToSlug = $row[0];
my $strIDofURL = $row[1];
$strTargetToSlug =~ s/.*?([^/.]+).aspx$/$1/i;
$strTargetToSlug =~ s/[^a-zA-Z0-9]+/-/g;
$strTargetToSlug =~ s/^-*(.*?)-*$/$1/;
if (exists $dictSlugToID{$strTargetToSlug})
{
print "IsLink: URL ID " . $strIDofURL . " links to Post ID " . $dictSlugToID{$strTargetToSlug} . " via Slug " . $strTargetToSlug . "
";
$dictURLIDToPostID{$strIDofURL} = $dictSlugToID{$strTargetToSlug};
}
else
{
print "IsLink: Could not find matching Slug " . $strTargetToSlug . "
";
}
}
foreach my $strURLID ( keys %dictURLIDToPostID )
{
print "URL: $strURLID, Links To Post: $dictURLIDToPostID{$strURLID}
";
$dbh-≻do(
'INSERT INTO PostURL (URLID, PostID, IsLink ) VALUES (?, ?, ?)', undef,
$strURLID,
$dictURLIDToPostID{$strURLID},
1);
}
}
Here is what the routine printed while running:
IsLink: URL ID 14 links to Post ID 321 via Slug City-at-night
IsLink: URL ID 27 links to Post ID 268 via Slug Reply-to-Lucie
IsLink: URL ID 45 links to Post ID 381 via Slug The-Wild-Garden
IsLink: URL ID 66 links to Post ID 47 via Slug Pauls-Scarlet
IsLink: URL ID 130 links to Post ID 349 via Slug Jens-Alphabet-J
...
URL: 480, Links To Post: 166
URL: 27, Links To Post: 268
URL: 14, Links To Post: 321
URL: 45, Links To Post: 381
URL: 471, Links To Post: 314
...
And now finally we can use this in the URL resolve routine in the PHP page. On line 13 I added IsFileContent. Then the additional query between line 35 and 45 was added.
# http://www.jens.malmgren.nl/post/Porting-my-blog-for-the-second-time-render-posts-part-6.aspx
# http://www.jens.malmgren.nl/post/Porting-my-blog-for-the-second-time-render-posts-part-9.aspx
preg_match_all("/({URL:[0-9]+})/", $strContent, $matches, PREG_OFFSET_CAPTURE );
$matches_terms = $matches[1];
for ($i = count($matches_terms) - 1; $i ≻= 0; $i--)
{
$match_term_position = $matches_terms[$i];
$match_term = $match_term_position[0];
$match_position = $match_term_position[1];
$strDataBaseLookupId = preg_replace("/{URL:([0-9]+)}/", "$1", $match_term);
$query = "SELECT FileName, IsLocalURL, Target, IsFileContent FROM URL WHERE ID = '$strDataBaseLookupId'";
$result = $mysqli-≻query($query) or die("Error query.." . mysqli_error($mysqli));
$strFileName = "?";
$iIsLocalURL = 1;
$strTarget = "";
$iIsFileContent = 0;
if ($row = mysqli_fetch_array($result))
{
$strFileName = $row["FileName"];
$iIsLocalURL = $row["IsLocalURL"];
$strTarget = $row["Target"];
$iIsFileContent = $row["IsFileContent"];
}
if ($iIsLocalURL)
{
if ($iIsFileContent)
{
$strContent = substr_replace($strContent, '/images/' . $strFileName, $match_position, strlen($match_term));
}
else
{
$query = "SELECT p.Slug FROM URL u, PostURL pu, Post p WHERE u.ID = '$strDataBaseLookupId' AND u.ID = pu.URLID AND pu.PostID = p.ID AND pu.IsLink = 1;";
$result = $mysqli-≻query($query) or die("Error query.." . mysqli_error($mysqli));
$strSlugOfPostLinkingTo = "NotResolved";
if ($row = mysqli_fetch_array($result))
{
$strSlugOfPostLinkingTo = $row["Slug"];
}
$strContent = substr_replace($strContent, '/post/' . $strSlugOfPostLinkingTo, $match_position, strlen($match_term));
}
}
else
{
$strContent = substr_replace($strContent, $strTarget, $match_position, strlen($match_term));
}
}
Now with this method if I want to change the slug of a post even if there are internal links to it then those links will be automatically updated. Here is an example of how an internal link looks like:

It works!
Next I will go after some images that got rendered incorrectly.











 Sounds in the blogsystemNext version of the slideshowLearning Python Part IIILearning Python Part IIImpressionism and beyond. A Wonderful Journey 28 January 2018Fixing unresolved links after editingThis is my summer 2016 blog!Porting my blog for the second time, linksPorting my blog for the second time, editing part 7Porting my blog for the second time, editing part 6Porting my blog for the second time, categories part 3Business cards, version 1Porting my blog for the second time, deployment part 2Not indexed but still missing? Google hypocrisy.A new era: Nikon D5100 DSLR, Nikkor 18 - 55 and 55 - 300!
Sounds in the blogsystemNext version of the slideshowLearning Python Part IIILearning Python Part IIImpressionism and beyond. A Wonderful Journey 28 January 2018Fixing unresolved links after editingThis is my summer 2016 blog!Porting my blog for the second time, linksPorting my blog for the second time, editing part 7Porting my blog for the second time, editing part 6Porting my blog for the second time, categories part 3Business cards, version 1Porting my blog for the second time, deployment part 2Not indexed but still missing? Google hypocrisy.A new era: Nikon D5100 DSLR, Nikkor 18 - 55 and 55 - 300! I moved from Sweden to The Netherlands in 1995.
I moved from Sweden to The Netherlands in 1995.
Here on this site, you find my creations because that is what I do. I create.