| Porting my blog for the second time, walk the old data part 2 |
Porting my blog for the second time, walk the old data part 4 |
Porting my blog for the second time, walk the old data part 3
This is post #15 of my series about how I port this blog from Blogengine.NET 2.5 ASPX on a Windows Server 2003 to a Linux Ubuntu server, Apache2, MySQL and PHP. A so called LAMP. The introduction to this project can be found in this blog post /post/Porting-my-blog-for-the-second-time-Project-can-start.
In my previous post I started walking the directory and after 37 posts it crashed and I discovered I had forgotten about the built-in method you can use to insert images in BlogEngine.NET. The image URL of these images looks like this
≺code class="xml plain"≻≺≺/code≻≺code class="xml keyword"≻img≺/code≻ ≺code class="xml color1"≻src≺/code≻≺code class="xml plain"≻=≺/code≻≺code class="xml string"≻"/image.axd?picture=2011%2f9%2fJens+Blog+QR.png"≺/code≻ ≺code class="xml color1"≻alt≺/code≻≺code class="xml plain"≻=≺/code≻≺code class="xml string"≻""≺/code≻ ≺code class="xml plain"≻/≻≺/code≻
There were several issues with this. My routine detecting if a link is going to become a local link did not see this. I changed that into this:
# http://www.jens.malmgren.nl/post/Porting-my-blog-for-the-second-time-walk-the-old-data-part-3.aspx # http://www.jens.malmgren.nl/post/Porting-my-blog-for-the-second-time-images-part-4.aspx $bIsLocalURL = $tag =~ /(malmgren.nl|blogspot.com|googleusercontent.com|/image.axd)/i;
The tag detection routine only looked at URLs starting with HTTP and now it had to look for links starting with /image.axd as well.
# Replace an URL with an URL place holder. Store the URL in dictURLToDatabaseID so that
# later on it is possible to search for URLs a second time.
# http://www.jens.malmgren.nl/post/Porting-my-blog-for-the-second-time-walk-the-old-data-part-3.aspx
# http://www.jens.malmgren.nl/post/Porting-my-blog-for-the-second-time-images-part-3.aspx
my $iDatabaseIDofThisURLentry = -1;
if ($tag =~ /(.*?)(https?://|/image.axd?)(.+?)["']/i)
{
my $strParsedURL = $2.$3;
$strTarget = uri_decode($strParsedURL);
$strTarget =~ s//image/http://www.jens.malmgren.nl/image/;
In case I found this /image... links I had to make the link absolute so that I could fetch the image file with LWP::Simple. I did this with a search replace operation.
It worked! I could start walking again. Now my program could walk all the way to post 60 and downloading 174 images.
So now this is getting tedious. I know there is an error but I don't know exactly where the error is, how far the program has come in processing the URLs. So before I can find the error I need a rock solid method of calculating the offset into the content I am processing. For this I had to create a new variable $contentParsed storing the part of the content that we already parsed.
# URL and Image processing
# Here we parse the post content. Extract URLs and store these in the URL entity.
# Download images to be stored locally. Find and replace all URLs with URL place holders.
# http://www.jens.malmgren.nl/post/Porting-my-blog-for-the-second-time-walk-the-old-data-part-3.aspx
# http://www.jens.malmgren.nl/post/Porting-my-blog-for-the-second-time-images-part-1.aspx
my $iUrlCount = 0;
my $content = $dictStringFieldToValue{"content"};
my $contentParsed = "";
my $contentResult = "";
while ($content =~ /^(.*?)(≺a.+?≻|≺img.+?/≻)/msi)
{
print "~-~-~-~-~-~-~-~-~-~-~-~-~-~-~-~-~-~-
";
print "~-~-~-~-~-~ PROCESS URL ~-~-~-~-~-~-
";
print "~-~-~-~-~-~-~- START -~-~-~-~-~-~-~-
";
$iUrlCount++;
$content = substr($content, length($1 . $2));
$contentParsed .= $1;
$contentResult .= $1; # Wait with saving the tag until after it has been replaced with a place holder.
my $tag = $2;
print "Tag at offset : " . length($contentParsed =~ s/
/
/r) . "
";
$contentParsed .= $tag;
$bIsAlreadyLoadedInAnotherPost = 0;
On Linux the default line separator is one linefeed but on windows it is carriage return and a line feed. If I calculate the offset based on what I am reading in Linux and then view the file on a windows machine then I don't get spot on the location. So I replace with so that the offsets are windows compatible. I do this with the non destructive substitution modifier /r.
So when I had done this it was really easy to find out I had yet another method for storing images on my previous blog, images I stored locally and most of these I stored in a subdirectory called Images.
So we already had the situation /image... covered and now we have /Image... So that is almost the same!
# http://www.jens.malmgren.nl/post/Porting-my-blog-for-the-second-time-walk-the-old-data-part-3.aspx # http://www.jens.malmgren.nl/post/Porting-my-blog-for-the-second-time-images-part-4.aspx $bIsLocalURL = $tag =~ /(malmgren.nl|blogspot.com|googleusercontent.com|/image)/i;
With case insensitive search /i it is possible to find both cases.
# Replace an URL with an URL place holder. Store the URL in dictURLToDatabaseID so that
# later on it is possible to search for URLs a second time.
# http://www.jens.malmgren.nl/post/Porting-my-blog-for-the-second-time-walk-the-old-data-part-3.aspx
# http://www.jens.malmgren.nl/post/Porting-my-blog-for-the-second-time-images-part-3.aspx
my $iDatabaseIDofThisURLentry = -1;
if ($tag =~ /(.*?)(https?://|/image)(.+?)["']/i)
{
my $strParsedURL = $2.$3;
$strTarget = uri_decode($strParsedURL);
$strTarget =~ s//([iI])mage/http://www.jens.malmgren.nl/$1mage/;
Here I can find both i and I with [iI] and then I save it in a parenthesis so that when I replace the target URL so that it becomes absolute then I insert the correct casing i.
So now I can start walk again...
Now I came to post 82 before the program choked.
~-~-~-~-~-~-~-~-~-~-~-~-~-~-~-~-~-~- ~-~-~-~-~-~ PROCESS URL ~-~-~-~-~-~- ~-~-~-~-~-~-~- START -~-~-~-~-~-~-~- Tag at offset : 9610 Already present: https://lh5.googleusercontent.com/-2L5JYN1sxy8/TzgaXqHaeQI/AAAAAAAABjU/culLZDw1BVQ/s1600/DSC_2738.JPG|a DBD::mysql::db do failed: Duplicate entry '82-225' for key 'PRIMARY' at /usr/local/bin/analyze.pl line 314. DBD::mysql::db do failed: Duplicate entry '82-225' for key 'PRIMARY' at /usr/local/bin/analyze.pl line 314.
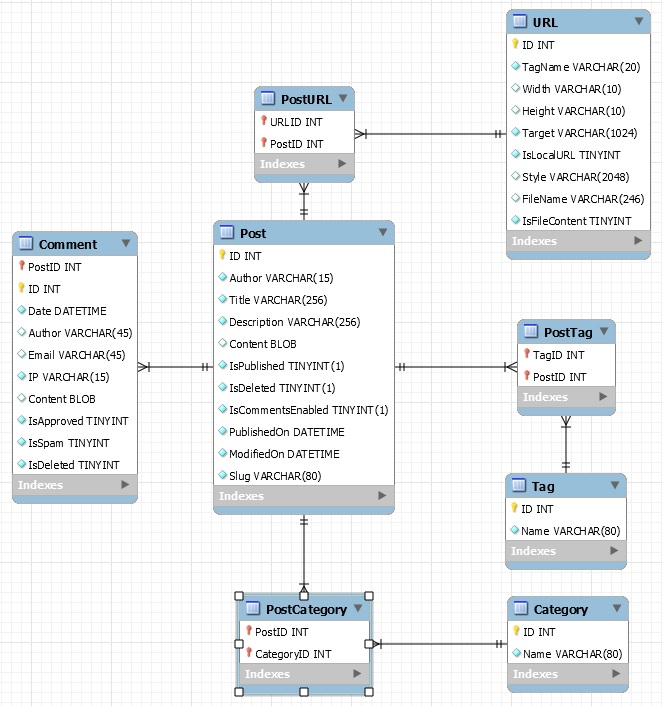
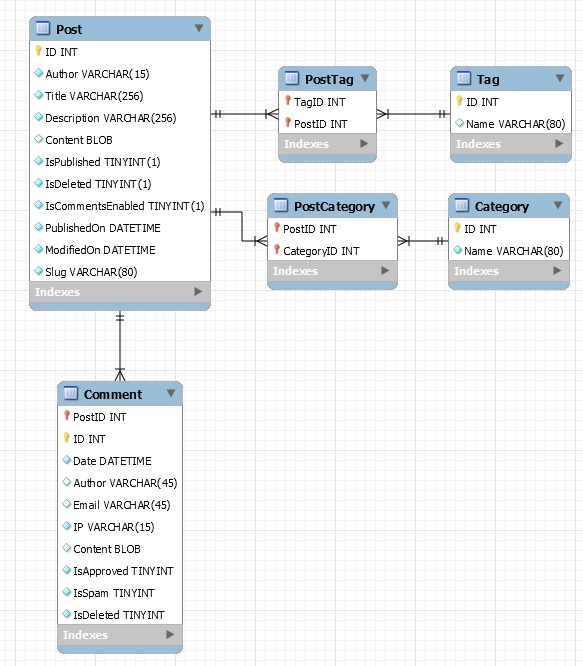
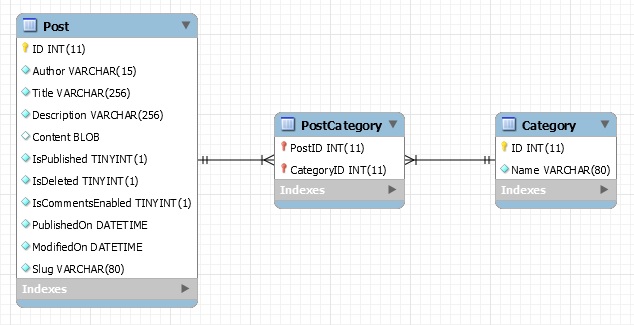
This was slightly harder problem. What MySQL is saying here is that for post ID 82 we already created a link to URL 225. So with other words if there is a post using the same URL twice in the same post then it is not possible to setup another link. This is logical. Had not thought about it before. I could solve this in a complex way or in an easy way. I go for the easy way. That is to "ignore" the problem. Found the way to do that with DBI in Perl.
# Ignore duplicates of links between a Post and URL because that indicated that the same URL is used twize in a post.
# http://www.jens.malmgren.nl/post/Porting-my-blog-for-the-second-time-walk-the-old-data-part-3.aspx
eval {
$dbh-≻do(
'INSERT INTO PostURL (URLID, PostID )' .
'VALUES (?, ? )' , undef,
$iDatabaseIDofThisURLentry,$postID);
};
print "PostURL already available. PostID: " . $postID . ", URLID: " . $iDatabaseIDofThisURLentry . ". Message: $@
" if $@;
And the result looks like this:
~-~-~-~-~-~-~-~-~-~-~-~-~-~-~-~-~-~- ~-~-~-~-~-~ PROCESS URL ~-~-~-~-~-~- ~-~-~-~-~-~-~- START -~-~-~-~-~-~-~- Tag at offset : 9610 Already present: https://lh5.googleusercontent.com/-2L5JYN1sxy8/TzgaXqHaeQI/AAAAAAAABjU/culLZDw1BVQ/s1600/DSC_2738.JPG|a DBD::mysql::db do failed: Duplicate entry '1-1' for key 'PRIMARY' at /usr/local/bin/analyze.pl line 316. PostURL already available. PostID: 1, URLID: 1. Message: DBD::mysql::db do failed: Duplicate entry '1-1' for key 'PRIMARY' at /usr/local/bin/analyze.pl line 316.
This is when I tried only loading this post so here the PostID was 1 and URL ID was 1 as well. Now I can walk again...
And how that walking ended and where... that is for the next time.











 Sounds in the blogsystemNext version of the slideshowLearning Python Part IIILearning Python Part IIImpressionism and beyond. A Wonderful Journey 28 January 2018Fixing unresolved links after editingThis is my summer 2016 blog!Porting my blog for the second time, linksPorting my blog for the second time, editing part 7Porting my blog for the second time, editing part 6Porting my blog for the second time, categories part 3Business cards, version 1Porting my blog for the second time, deployment part 2Not indexed but still missing? Google hypocrisy.A new era: Nikon D5100 DSLR, Nikkor 18 - 55 and 55 - 300!
Sounds in the blogsystemNext version of the slideshowLearning Python Part IIILearning Python Part IIImpressionism and beyond. A Wonderful Journey 28 January 2018Fixing unresolved links after editingThis is my summer 2016 blog!Porting my blog for the second time, linksPorting my blog for the second time, editing part 7Porting my blog for the second time, editing part 6Porting my blog for the second time, categories part 3Business cards, version 1Porting my blog for the second time, deployment part 2Not indexed but still missing? Google hypocrisy.A new era: Nikon D5100 DSLR, Nikkor 18 - 55 and 55 - 300! I moved from Sweden to The Netherlands in 1995.
I moved from Sweden to The Netherlands in 1995.
Here on this site, you find my creations because that is what I do. I create.