| Porting my blog for the second time, walk the old data part 3 |
Porting my blog for the second time, finished loading old blog data |
Porting my blog for the second time, walk the old data part 4
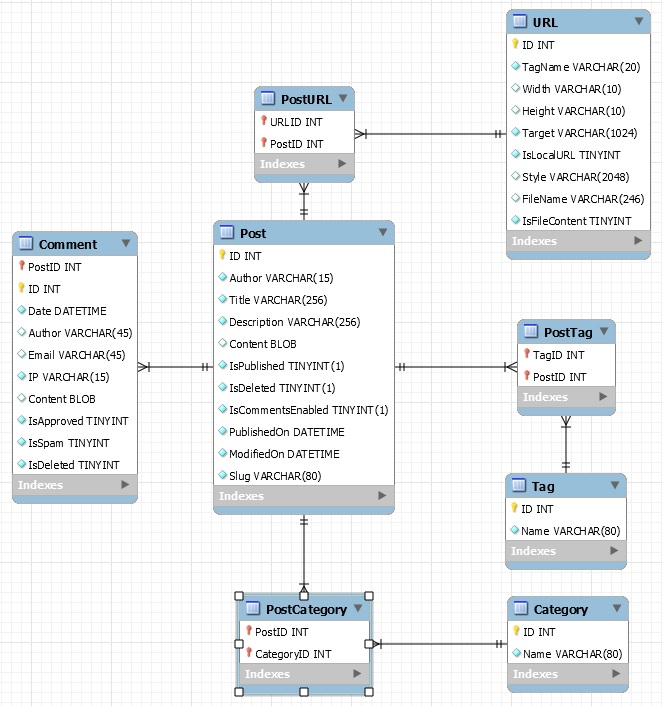
This is post #16 of my series about how I port this blog from Blogengine.NET 2.5 ASPX on a Windows Server 2003 to a Linux Ubuntu server, Apache2, MySQL and PHP. A so called LAMP. The introduction to this project can be found in this blog post https://www.malmgren.nl/post/Porting-my-blog-for-the-second-time-Project-can-start.aspx.
I am in the midst of loading all my post files from my previous blog into the database. All sorts of problems I have not thought about makes my program crash. For every crash I fix the problem and starts walking again. My routine is called walk since it is "walking" over an directory of files.
≺pre≻DBD::mysql::db do failed: Duplicate entry 'Glass-vases' for key 'Slug' at /usr/local/bin/analyze.pl line 153.
DBD::mysql::db do failed: Duplicate entry 'Glass-vases' for key 'Slug' at /usr/local/bin/analyze.pl line 153.
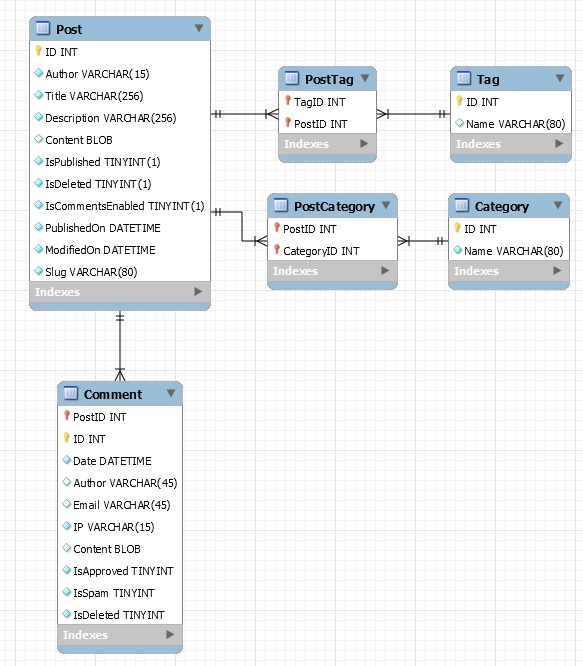
Lets talk about the slug for a moment. In the previous blog something called slug was used as a basis for the filename used to identify the blog post. That works. It is however a really bad idea to have duplicate slug names in a blog site because what entry are we referring to with that name? So I made the slug entry unique in the database. I wonder how the people of BlogEngine.NET where thinking when making it possible to have duplicate slug names.
So here I am. My previous blog got two Glass-vases entries in the XML files and my database cannot handle it. At post 126 the program chokes.
One thing is clear, I need to modify the slug name if it is a duplicate name. Then how to go about and detect that a slug is duplicate that can be done in a MySQL way or a Perl way. The MySQL way is a bit "expensive" because I need to emit an insert and it will need to fail before I can emit a modified insert. Somehow I don't like that idea. In a situation where my program was made to work on partial entries then I had to use the MySQL way. I had to query the database before I would know it a slug already exists. My program on the other hand works on the entire database. It is easier to let the program remember what slugs it already got. When doing it that way I can adjust the slug already before the Insert and then I would need just one single insert and it would never fail.
I know that if I at some point in the future had to import a bunch of posts per day then I would need to change this but I think I will just run this program once and when I am happy with the result I don't need to use this program anymore. So... I will make my program remember slugs.
While at it I noticed that I have slugs starting with a dash and that is not good, I can fix that.
At the beginning of the program I define a hash table
# For detection of duplicate slug names. # http://www.jens.malmgren.nl/post/Porting-my-blog-for-the-second-time-walk-the-old-data-part-4.aspx my %dictSlugToID = ();
Then right before inserting the post we check the slug if it is unique and if it needs some clean up.
# Clean up the slug. Resolve duplicate slug names.
# http://www.jens.malmgren.nl/post/Porting-my-blog-for-the-second-time-walk-the-old-data-part-4.aspx
$dictStringFieldToValue{"slug"} =~ s/^\-?(.*)\-?$/$1/;
$dictStringFieldToValue{"title"} =~ s/^\s?(.*)\s?$/$1/;
my $iSlugCounter = 2;
while (exists ($dictSlugToID{$dictStringFieldToValue{"slug"}}))
{
$dictStringFieldToValue{"slug"} = $dictStringFieldToValue{"slug"} . "-" . $iSlugCounter;
$iSlugCounter++;
}
print "Slug: " . $dictStringFieldToValue{"slug"} . "\n";
After the insert we set the dictToSlugID as such:
# Remember this slug.
# http://www.jens.malmgren.nl/post/Porting-my-blog-for-the-second-time-walk-the-old-data-part-4.aspx
$dictSlugToID{$dictStringFieldToValue{"slug"}} = $postID;
With this solution the problem was solved and I could start walking again.
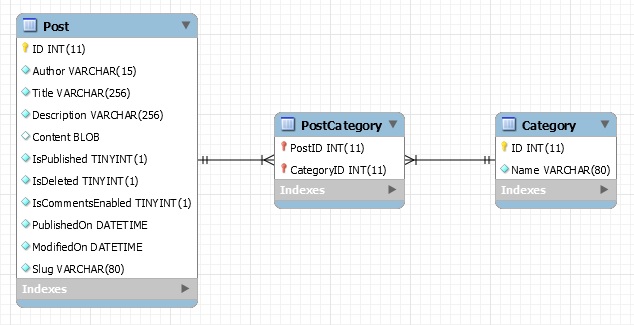
This time the program stopped at post 319. This time it was because the category was unknown. That is an unusual error but ok, what could that be? It turned out to be an example blog post of the BlogEngine.NET. For this I just skip this file. I insert this in my Walk directory routine:
# Skip this file. The welcome message of the BlogEngine.
# http://www.jens.malmgren.nl/post/Porting-my-blog-for-the-second-time-walk-the-old-data-part-4.aspx
if ($dirItem =~ /c3b491e5-59ac-4f6a-81e5-27e971b903ed.xml/)
{
next;
}
I have this feeling that I am close to reach the finish but before walking again I would like to get one thing improved. As it is now the XML files contains text encoded with HTML entities. I don't need that. I am perfectly fine with using Unicode characters. Do I have words for how old fashioned it is with people who don't use Unicode. What's wrong with you? Anyway, I need those entities converted to real characters. To do that I am going to use the package HTML::Entities.
So here we go again. How do I get that perl package downloaded to my Ubuntu? Do you remember? Nope. I wrote about it in this blog post: https://www.malmgren.nl/post/Porting-my-blog-for-the-second-time-walk-the-old-data.aspx.
I tried to get HTML::Entities but that failed. Then I found it was part of a larger package HTML::Parser and that I could get with this command apt-get install libhtml-parser-perl and that was already installed. It is so easy when you already know everything. Pfff...
# Decode entities
# http://www.jens.malmgren.nl/post/Porting-my-blog-for-the-second-time-walk-the-old-data-part-4.aspx
$dictStringFieldToValue{"content"} = decode_entities($dictStringFieldToValue{"content"}, "\200-\377");
The decoding takes place before I parse the URLs.
So now I could start walk again. The server went on and on and on. For each post I could here the hard disk spin and when it was downloading images it was silent and then it went on again and so it continued for a long time. I made myself a cup of tea.
Then there was silence. The program had finished. It had downloaded 1255 images. It had created 433 posts. It had stored 139 feedback entries.
I am delighted. My program walked all the way to the finish!
So here starts the next challenge. Turn this data into a blog. But... that is for next time.











 Sounds in the blogsystemNext version of the slideshowLearning Python Part IIILearning Python Part IIImpressionism and beyond. A Wonderful Journey 28 January 2018Fixing unresolved links after editingThis is my summer 2016 blog!Porting my blog for the second time, linksPorting my blog for the second time, editing part 7Porting my blog for the second time, editing part 6Porting my blog for the second time, categories part 3Business cards, version 1Porting my blog for the second time, deployment part 2Not indexed but still missing? Google hypocrisy.A new era: Nikon D5100 DSLR, Nikkor 18 - 55 and 55 - 300!
Sounds in the blogsystemNext version of the slideshowLearning Python Part IIILearning Python Part IIImpressionism and beyond. A Wonderful Journey 28 January 2018Fixing unresolved links after editingThis is my summer 2016 blog!Porting my blog for the second time, linksPorting my blog for the second time, editing part 7Porting my blog for the second time, editing part 6Porting my blog for the second time, categories part 3Business cards, version 1Porting my blog for the second time, deployment part 2Not indexed but still missing? Google hypocrisy.A new era: Nikon D5100 DSLR, Nikkor 18 - 55 and 55 - 300! I moved from Sweden to The Netherlands in 1995.
I moved from Sweden to The Netherlands in 1995.
Here on this site, you find my creations because that is what I do. I create.